 statistic fdr
statistic fdr A distributed trace, on the other hand, occurs only at the application layer and provides visibility into a request as it flows across service boundaries.
dependable Distributed Tracing: the Right Framework and Getting Started, Introduction to Distributed Tracing in Modern Applications, Distributed Tracing: Manual vs. Automatic, Common Design Patterns in Distributed Architectures, Stay up to date with our newest product: Telescope, How to Make AWS Lambda Faster: Memory Performance. Instead of trying to repurpose your existing tools or methods or building your own, you can use a cloud-based service such as Epsagon. As that number grows, so does the need for distributed tracing and improved observability. Because microservices scale independently, its common to have multiple iterations of a single service running across different servers, locations, and environments simultaneously, creating a complex web through which a request must travel.
opentracing opentelemetry In this article, well cover how distributed tracing works, why its helpful, and tools to help you get started. However, traces dont explain the root cause of a service error or latency. Open source and free, you can implement the entire stack or use the tools individually. This website uses cookies to improve your experience while you navigate through the website. 86% of global IT leaders in a recent IDG survey find it very, or extremely, challenging to optimize their IT resources to meet changing business demands. For this, you need to investigate the application logs. Kafka is a distributed streaming platform, providing a high-throughput, low-latency platform for handling real-time data feeds, often used in microservice architectures. Centralized logging collects and aggregates logs from multiple services into a central location where they are indexed in a database. Distributed tracing, sometimes called distributed request tracing, is a method to monitor applications built on a microservices architecture. The Bottom Line: Distributed Tracing Is Essential For Distributed Apps. Distributed tracing helps measure the time it takes to complete key user actions, such as purchasing an item. Though this provided much-desired flexibility, the APIs sole focus on tracing made it of limited use on its own and led to inconsistent implementations by developers and vendors. Some log storage systems also work more reliably when they are closer to the device generating the log files. However, as the industry starts adopting microservice architectures, logging alone cannot effectively troubleshoot issues. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. Transform your business in the cloud with Splunk. Figure 1: Tracing an external request using the Jaeger UI. Its critical to filter log messages into various logging levels, such as Error, Warn, Info, Debug, and Trace, as this helps developers understand the data better and set up necessary monitoring alerts.
 microservices
microservices In microservice architecture, an application is broken down into modular services, each of which handles a core function of the application and is often managed by a dedicated team.

Tags to query and filter requests by session ID, database host, HTTP method, and other identifiers. And with Datadogs unified platform, you can easily correlate traces with logs, infrastructure metrics, code profiles, and other telemetry data to quickly resolve issues without any context switching. Using modern, standard approaches to cloud software development can both improve your building speed and reduce the setup and maintenance of observability, as it will be automated by corresponding modern tools. As with similar tools, AWS X-Ray traces user requests through an application, collecting data that can help find the cause of latency issues, errors, and other problems. In monolithic systems, the transaction happens in the same machine, and traditional logging generally provides the full execution stack trace, which can assist in troubleshooting any service error. Metrics and logging provide context from a single application, whereas distributed tracing helps track a request as it traverses through many inter-dependent applications.

Having a standardized way of logging goes a long way in achieving consistency and provides better insight into your system. Logs can originate from the application, infrastructure, or network layer, and each time stamped log summarizes a specific event in your system.
cdf empirical Tracing or monitoring, at least for now, may be beneficial but not necessities; as you grow and need more functionality, one or both can be useful. Below is an example of how these libraries store the log information and send it to the log management system: Structured logging allows you to easily use your system for monitoring, troubleshooting, and business analytics. This approach results in missing and incomplete traces. We'll assume you're ok with this, but you can opt-out if you wish. Observability vs Monitoring: Whats The Difference? Unless you use an end-to-end distributed tracing platform, a trace ID is generated for a request only when it reaches the first backend service. Developers can also use the flame graph to determine which calls exhibited errors. This solution can also handle synchronous events, asynchronous events, and message queues. Since each span is timed, engineers can see how long the request spent in each service or database, and prioritize their troubleshooting efforts accordingly. Manual instrumentation consumes valuable engineering time and can introduce bugs in your application, but the need for it is often determined by the language or framework that you want to instrument. Unlike logging, localization is not a concern, but new messages do need to be agile. A data platform built for expansive data access, powerful analytics and automation, Cloud-powered insights for petabyte-scale data analytics across the hybrid cloud, Search, analysis and visualization for actionable insights from all of your data, Analytics-driven SIEM to quickly detect and respond to threats, Security orchestration, automation and response to supercharge your SOC, Instant visibility and accurate alerts for improved hybrid cloud performance, Full-fidelity tracing and always-on profiling to enhance app performance, AIOps, incident intelligence and full visibility to ensure service performance. A monolithic application is developed as a single functional unit. Customer success starts with data success. Metrics and logs by themselves fail to provide in-depth visibility across all the services, and this is where distributed tracing comes to the rescue. Logging levels allow you to categorize log messages into priority buckets. This website uses cookies to improve your experience. Modern distributed tracing tools typically support three phases of request tracing: First, you modify your code so requests can be recorded as they pass through your stack. This triggers the creation of a unique trace ID and an initial spancalled the parent spanin the tracing platform. What are the benefits of distributed tracing solutions? Multi-Cloud Best Practices: How IT Ops Can Champion, Thinking About a Cloud Migration Project? Heres How You Can Ensure Success, Data for us humans that alerts or warns of a panic situation (enough to begin the investigation but not an overwhelming amount), Structured data for machines (Some debate whether this machine-level data is necessary, but security is a good case use. Logging is primarily deployed and used by system administrators on the operational level, intentionally providing a high-level view. When there is an application issue, logs are your best friends and help to identify errors and understand what exactly went wrong. OpenCensus was developed at Google and was based on its internal tracing platform. Sometimes, tracing is best for microservices. Because of the data involved, tracing can be an expensive endeavor. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. Depending on the number of services you have, the effort to do this can be sizable. Jaeger and Zipkin are two popular open-source request tracing tools, each with similar components: a collector, datastore, query API, and web user interface. It can also trace messages, requests, and services from their source to their destinations. Based on your application landscape, you can determine if tracing provides added value from a monitoring perspective.
dashed empirical Keeping the game running smoothly would be unthinkable with traditional tracing methods. It must track each end user's location, each interaction with other players and the environment, every item the player acquires, end time, and a host of other in-game data.

Build resilience to meet todays unpredictable business challenges. Finally, the spans are unified into a single distributed trace and encoded with business-relevant tags for analysis. Cloud Monitoring: Choosing the Right Metrics, IT Infrastructure Capacity: Optimizing for Digital Maturity, What is Server Automation? AI vs Machine Learning: What's The Difference? Youll want to consider whether the added complexity is warranted, what value will it bring?
compensated langmuir Storing and parsing log data is an expensive operation, so its crucial to log only information that can help you identify issues and keep it manageable. These monitoring systems are surprisingly affordable, though they do rely heavily on data. By viewing distributed traces, developers can understand cause-and-effect relationships between services and optimize their performance. Microservices are used to build many modern applications because they make it easier to test and deploy quick updates and prevent a single point of failure. A log can be defined as a specific timestamped event that happened to your system at a particular time.
 logging kubernetes traces debug microservices aspecto devops languages requires
logging kubernetes traces debug microservices aspecto devops languages requires OpenTracing and OpenCensus competed as open source distributed tracing projects that were recently merged into a single tool called Open Telemetry. Distributed tracing is a critical component of observability in connected systems and focuses on performance monitoring and troubleshooting. However, OpenTelemetry does not have any built-in analysis or visualization tools. Instead log files should log only what is absolutely necessary, such as actionable items. The good news is that there is a better approach that gives you the ultimate solution.

The goal of tracing is to following a programs flow and data progression. These include: A distributed tracing tool like Zipkin or Jaeger (both of which we will explore in more detail in a bit) can correlate the data from all the spans and format them into visualizations that are available on request through a web interface. A distributed trace is defined as a collection of spans. Troubleshooting issues is difficult without access to application logs.
Since they sample traces, you may end up missing problems that are affecting your users. You can use Datadogs auto-instrumentation libraries to collect performance data or integrate Datadog with open source instrumentation and tracing tools. There are challenges to adding instrumentation to your application code across your entire stack. Analysts, SREs, developers and others can observe each iteration of a function, enabling them to conduct performance monitoring by seeing which instance of that function is causing the app to slow down or fail, and how to resolve it. With no API available to embed OpenCensus into code, developers used community-built automatic instrumentation agents for the task. Join us for Dash 2022 on October 18-19 in NYC! These include: What are the different types of tracing tools? Distributed logging may also be preferred for large-scale systems.

), Who is using the logs (typically sysadmins), Whether logging helps only with preventative measures or with ongoing pursuits. Its easy to install and has a clean interface that gives you a consolidated view of data from the browser, command line, or an API. Engineers can then analyze the traces generated by the affected service to quickly troubleshoot the problem. These requests are nearly impossible to track with traditional techniques designed for a single service application. Jaegers supported-language list is shorter: C#, Java, Node.js, Python, and Go.
Chrissy Kidd is a writer and editor who makes sense of theories and new developments in technology. The advantages of microservices for building cloud-based applications are well documented and adoption shows no signs of slowing. What Are the Benefits Of Distributed Tracing? It also comes with a RESTful API, allowing it to be integrated into other tools. Observability has evolved in the journey from monoliths to microservices.
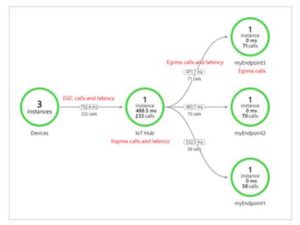
code iot diagnose distributed azure tracing hub issues visual studio When the user sends an initial request an HTTP request, to use a common example it is assigned a unique trace ID. It can be used in both an apps build stage and testing stages, as well as servicing the app once its in production. AWS X-Ray is the native distributed tracing tool for Amazon Web Services (AWS). The collector then records and correlates the data between different traces and sends it to a database where it can be queried and analyzed through the UI. Zipkin supports virtually every programming language with dedicated libraries for Java, Javascript, C, C++, C#, Python, Go, Scala, and others. It provides you an insight into an applications health end to end.

These cookies do not store any personal information. But it can be challenging to troubleshoot microservices because they often run on a complex, distributed backend, and requests may involve sequences of multiple service calls. A span is the smallest unit in a trace and represents a piece of the workflow in a distributed landscape. Having all relevant logs in one place greatly reduces the amount of time and energy developers must spend hunting down the root cause of an application issue. Its critical to filter log messages into various logging levels, such as Error, Warn, Info, Debug, and Trace, as this helps developers understand the data better and set up necessary monitoring alerts. Necessary cookies are absolutely essential for the website to function properly. There are a few reasons why this might be preferable to centralized logging.
correlation rno nonlinear radon earthquake Elastic (formerly ELK: ElasticSearch, Logstash, Kibana): One of the most popular stacks for distributed systems, Elastic combines three essential tools.
Sitemap 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}